
In this section, we cover different methods used to build the seedlist. We will go over several ways to identify and add entities to the seedlist, such as using public lists, lists from external stakeholders, and group research exercises. Then, we cover how to collect the handles and other demographic data for the collected entities.
Identifying Entities
Existing public lists
Some types of entities that you wish to include in your seedlist may be available publicly as an exhaustive list. For example, the complete list of elected politicians or registered charities can be found in official government-hosted websites. In such cases, we added the entities to the seedlist by downloading the list of entities from the official sources by scraping, using APIs (if provided), or point-and-click downloading, with automated methods being preferred.
External stakeholders
Another method of identifying entities to add to your seedlist may come from external subject matter experts. You may reach out to experts to provide you with a list of entities covering a specific topic or conversely, experts may sometimes come to you with and ask whether your team can collect data for their existing list of entities. In either scenario, ensure that you provide a clear documentation specifying the instructions for recording new entities and the criteria inclusion into the seedlist. After receiving a list of entities to add from an external stakeholder, your team should also review the list to ensure that they all meet the inclusion criteria.
Structured time-box activities
Lastly, there are some types of entities where it will not be possible to get the full list of entities. For example, it is impossible to find or build an exhaustive list of every single political influencer in Canada. In such a case, we recommend running a time-boxed activity that mixes methods of group brainstorming and snowballing. For example, we took the following steps to add Canadian influencers to our seedlist:
- Data reviewers and other volunteers were separated into small groups of two to three people, with each group covering different influencer topics. Our topics included leftist commentators, LGBTQ+ rights, women’s rights, Indigenous rights, Quebecois/French Canadians, immigration, and healthcare.
- The teams were given 45-60 minute sessions where participants could search freely for prominent influencers in their assigned topic. They utilized Google and online forums like Reddit or searched directly on the social media platforms. After identifying a prominent influencer, they used a snowballing technique to find other entities through retweets, shares, and mentions. They also utilized common keywords and hashtags for each topic and platform, such as #KeepFemaleSportsFemale, #EveryChildMatters, #PolitiqueQuebec, #CanadaFirst.
- As the teams searched for influencers, a live Google Document was shared with all the participants. The participants added useful hashtags, keywords, and any other helpful tips for finding entities in real time to help other team members with their search.
- On a separate Google Sheet, participants recorded the names and social media handles to be added to the seedlist. Since the list would be verified and enriched after the exercise, they focused on quantity over accuracy.
These time-box activities gave the teams the flexibility and creativity to find influencers. Participants were free to go down different rabbit holes and use any platform that they were most comfortable with. These activities also served as brainstorming sessions in which the team could share various methods and best practices for finding influencers. At the end of the exercise, the data reviewers reviewed the list of recorded entities, ensuring that they met the seedlist criteria and filled in any missing social media handles.
Finding and Verifying Seed Data
Verifying Entities
Identifying entities should be followed by a review to confirm they belong in the seedlist. In our process, research assistants verified that each entity met the criteria to be a seed using the Definitions and Criteria document from the planning stage, confirmed its main type, assigned a subtype, and collected basic demographic information such as province1.
The most fundamental requirement was that the entity be a person, group, or organization of substantive interest to Canada’s media ecosystem. There were additional checks, for example, if the seed represented a person, they had to be alive, groups had to be active, organizations had to be officially registered and still in operation, and media products had to be actively in production.
Some entity types required more specific checks. For civil society organizations, such as charities and labour unions, the research assistant was required to verify the organizations’ authenticity by searching for their organization number (e.g., charity number) or searching the organization on government websites (e.g., labour unions). This step allowed the research assistants to confirm that such organizations were registered and authorized in Canada.
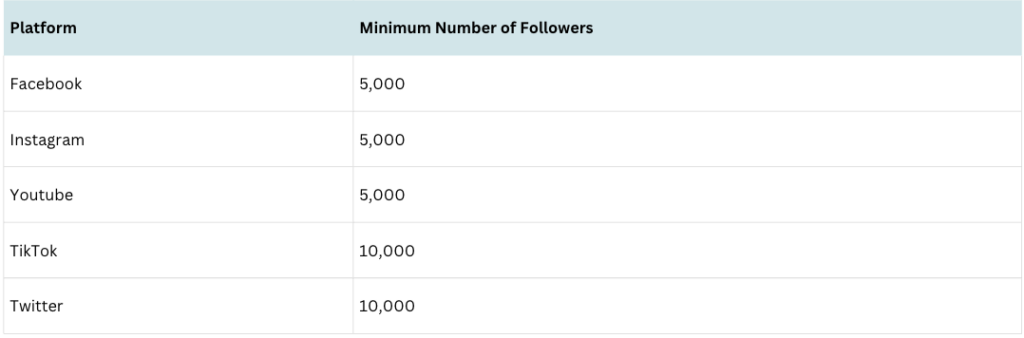
For influencers, we looked for evidence of active engagement with Canadian politics. Qualifying influencers had to be active on at least one social media platform in the past 12 months, with more than 25% of their content related to Canadian politics. Moreover, seeds needed to meet certain follower thresholds in at least one account and have at least a 1:2 following to follower ratio to exclude spam accounts. The full criteria, including definitions of main types and subtypes, are detailed in the “Definitions and Criteria” document (linked in the footnotes).
Finding Handles
Once the list of entities is ready, you will need to procure the social media handles for each entity. In some cases, social media handles may be available in the same source as the entities themselves. In other cases, you could employ an automated search followed by a manual review. We found that using Google search API to programmatically record the first handle search result for each entity to have around 10% false positive rate. These were then manually reviewed by data reviewers for mistakes and missing handles. This was done by manually searching for the entity online and finding links to their social media on their personal or professional websites. One thing to note in this process is that, on the basis of personal privacy, we do not recommend recording accounts that mainly contain personal content (daily life, family, pets, etc.). Since our research is in the field of political science, we only collected public accounts used to discuss politics.
The process for verifying entities coming from external stakeholders was similar to what was done for existing public lists. The research assistant began by verifying that the social media handles were accurate, as well as whether the entity met the requirements to be a seed. This process required more time because the lists were often incomplete, had the incorrect formatting, and were generally less standardized. As a result, the research assistant had to find the entity’s social media handles across multiple platforms, correct the formatting, and input both the seed’s maintype and subtype. Common formatting changes included replacing social media URLs with the correct social media handles and removing emojis or symbols from the entity’s name.

Finding Demographic Data
Finding and verifying seed data was done by performing an online search for the entity. The entity’s social media handles could often be found on their personal or professional websites. In addition, the research assistants verified seed data by checking the entity’s social media pages for links or Linktrees to their other social media accounts (X, Instagram, Facebook, Youtube, TikTok, Telegram, Bluesky).
Demographic data could then be found by finding identifying clues on the entity’s social media pages, such as their location in their Twitter and Facebook descriptions, as well as flag emojis on their pages (e.g., Canadian flag). In addition, a Google search could reveal demographic data about the entity, such as their year of birth and gender. Moreover, any additions or modifications to the seedlist would require peer review. In such cases, research assistants could review each other’s work and verify 10% of the seeds’ social media handles to ensure quality consistency and accurate work.
The methods listed above ensure that the seedlist remains accurate, standardized, and aligned with project goals. This ultimately allows researchers to create a strong foundation for data collection and analysis. In the next blog post, we will detail the necessary steps for maintaining a seedlist.
- You can find an example of our seedlist definitions and criteria document here: Seedlist Definitions and Criteria ↩︎
Leave a Reply