Before running crawlers or analyzing data, it is necessary to have clear and consistent data tables that define the entities in the ecosystem. In this section, we break down the components that make up a well-designed seedlist, including what each column should contain and how to format them, and how they relate to other columns.
ID
This is the primary key column used to identify each entity. It is also used to link entity information to the social media post data. Each entity should be assigned a unique and immutable ID in the seedlist data table. It may be tempting to use an entity’s name as an identifier, but this should be avoided because people and organizations can have the same name. The actual format of the ID is up to you – a number, string, or hash – but the format should stay consistent for the entire dataset and for any future entities added. In our seedlist, we have chosen a numeric value that increments by 1 for each new record as the ID.
Name
The name column is simply the name of the entity. For a person, this would be their full name, and for an organization, this would be their legal business name. The name column of the seedlist should follow a set of formatting rules around capitalization, abbreviations, and non-alphanumeric characters.
For entities that are people, decide on:
- The order of first and last names
- The inclusion of middle names, prefixes, and suffixes
- Usages of aliases if a person’s legal name is not public
- The language or alphabet to use, for multilingual entities
For entities that are organizations, decide on:
- How to handle abbreviations
- How to handle non-alphanumeric characters, like hyphens and parentheses
- Which language or alphabet to use, for multilingual entities
In rare cases, a name might not be disclosed in social media. For such cases, decide on whether to use the social media handle (and which handle) as a replacement or to leave the name blank.
Demographic Data Columns (Main Type, Sub-Type, Province, Provincial Party, Federal Party, etc.)
Demographic data is descriptive information about each entity that can be used to group and breakdown analysis results as well as be used to explore relationships between entity behavior and entity characteristics. Depending on your project’s requirements, you may have as many or as few demographic columns as you need. Some examples of the demographic columns we have are: type, province, and political party. Demographic data is only as useful as it is consistent. Each demographic column should have clear descriptions on whether they are mandatory or optional, what the possible values are (including spelling and case rules), and how to assign those values.
Unless your team is collecting only one type of entity, the seedlist should include an entity-type field. Moreover, since an entity must meet the criteria and definition of a seed type for inclusion in the seedlist, this field should never be left blank. In our seedlist, we called this variable “Main Type” and its possible values were “politician”, “influencer”, “civil society organization”, “government organization”, “news outlet”, and “foreign”. Other demographic data columns that we currently include in our seedlist are “Sub Type”, “Province”, “Provincial Party”, “Federal Party”, and “Electoral Riding”. Although it is possible to add new demographic columns to the seedlist, it is better to establish them as early as possible because backfilling values for the new column for existing entities can be time costly.
Some of the demographic columns may be dependent on the value of another column. For example, in our seedlist, an entity’s “Provincial Party” value determines its “Federal Party” value based on the provincial party’s relationship and alignment with a specific federal party. In cases like this, it is useful to have a mapping of the related categorical variables.
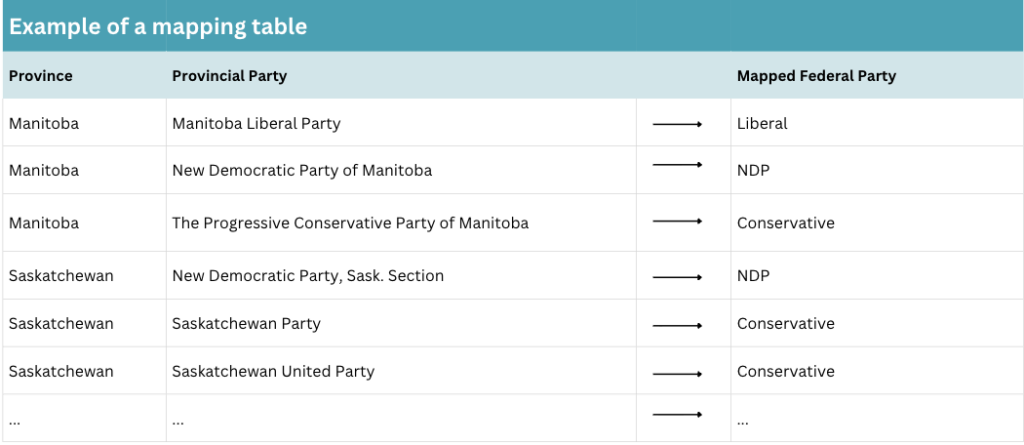
Whenever a demographic column has a limited set of possible values, we recommended choosing a single authoritative source for naming conventions. For example, we chose each province’s official election governing body (e.g., Elections Ontario) as the source of truth for the “Provincial Party” column and only used the official party names registered there. This will help minimize inconsistencies in spelling and abbreviations and also reduce data cleaning time.
Seed Status
Entities may become deactivated for a number of reasons, such as the deletion of their social media, no longer meeting the seedlist criteria, disbandment, or death. On the other hand, it is also probable that you will eventually discover that a few of the entities were added by error. Therefore, it is recommended to have a column that records an entity’s status in the seedlist. Keeping inactive or incorrect entities in the seedlist is preferable to deleting the record entirely for two main reasons. First, it allows you to link past posts to the correct entity. Even if an entity is now inactive, their past posts may still be relevant. Second, having a list of excluded entities makes it easier to avoid redundant verification efforts, so the same accounts aren’t repeated reconsidered for inclusion. In our seedlist, we label active seeds as “1”, inactive seeds as “0”, and deleted seeds as “-1”.
Social Media Handles
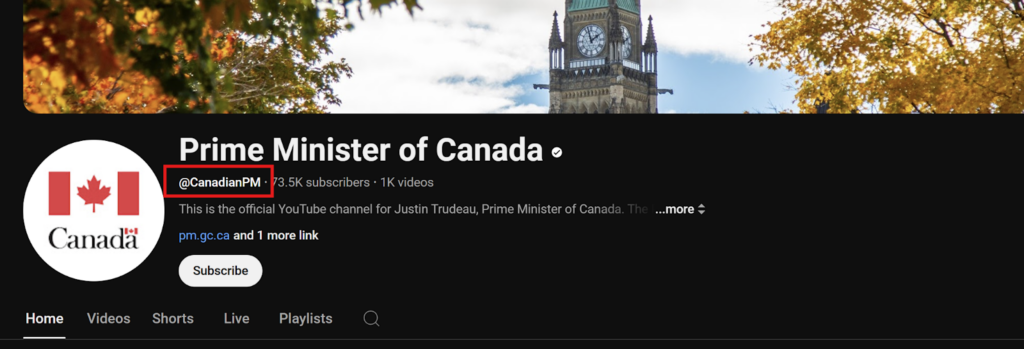
The social media handle columns are the most important columns in the seedlist since they inform the crawlers where to collect data from for each platform. Therefore, these are columns that should be the most accurate in terms of content and format. Your team should establish rules on whether these columns should contain handles or URLs. For URLs, there should be rules on whether the prefix should be included, which domain to use (x.com vs twitter.com, etc.), and whether it should include a trailing slash (“/”). Collecting URLs will require more rules to set and follow, so we recommend using handles over URLs. Some platforms, such as Youtube and Facebook, have multiple handle formats. There should be instructions for the data reviewers on which handle format should be recorded in the seedlist. For example, for Youtube, we have specified that the handle we collect is the handle starting with “@” under the channel name in the channel’s main page.
Timestamp Columns
Lastly, it is good practice to always include a timestamp of when the record was last edited. For deactivated entities, we would recommend including a “Deactivation Date” column to record when the entity was deactivated.
This work ensures consistency among the seedlist, enabling a smoother data cleaning and analyzing process. In the next post, we will describe the different methods of building a seedlist.
Leave a Reply