
Before building a seedlist, it is important to understand what resources are needed. In this blog, we outline the key prerequisites, including the necessary technical tools, the team roles involved, the time investment required, and the planning necessary to set the project up for success.
The seedlist and its place in the data collection pipeline
At its core, the seedlist is a data table that consists of a unique identifier for each entity and their social media handles (with a separate column for each platform). Other helpful demographic data, such as the entity name, type of entity, and their location, can also be added as columns. The seedlist plays an important role at the beginning and end of an entity-centered social media data collection. At the start of the pipeline, it informs each platform-specific crawler which social media handles it needs to collect data from. It also enables the crawlers to tag every collected post with the correct entity ID for merging later. At the end of the data collection pipeline, the same entity ID is used to join the post data to demographic variables so that the data can be aggregated and analysed as needed.
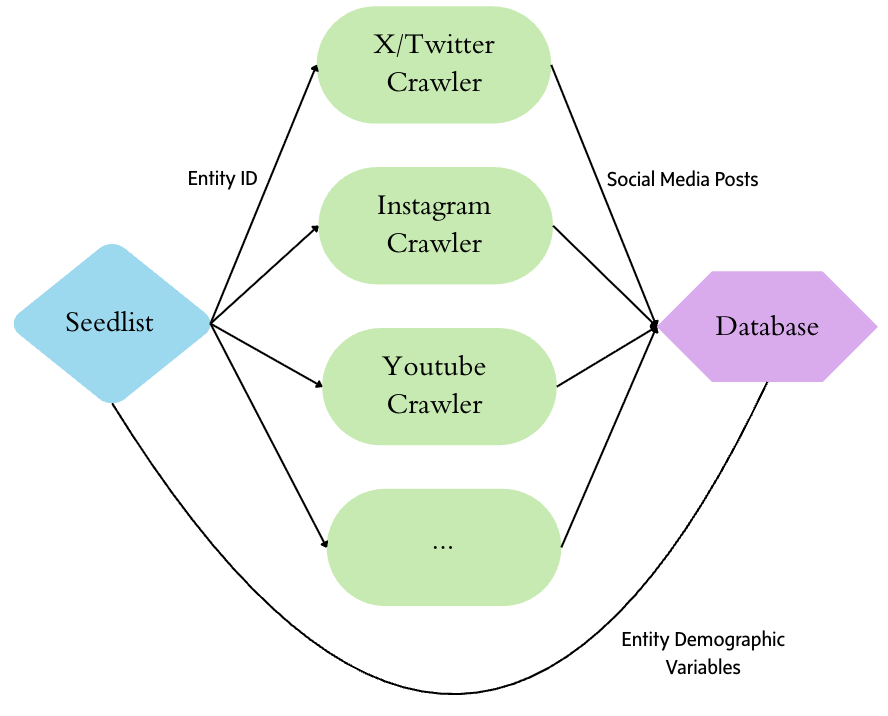
Technical requirements
Several technical tools are required for the creation, maintenance, and use of the seedlist. First, a spreadsheet tool is needed for the initial stage of manual data collection. A spreadsheet is a requirement for this initial stage given that it tends to involve individuals without extensive coding experience. We mainly used Google Sheets for its ease of collaboration, but other spreadsheet tools would suffice too.
Secondly, a programmatic data analysis tool such as Python, R, or SQL is needed for the assembly and maintenance of the seedlist. This tool will be used to transform the manually collected seedlist into a structure suitable for data crawler ingestion and then to transmit the transformed seedlist to the data crawlers. We used Python for our seedlist. A relational database management system (RDBMS), such as a SQL database, could be more suitable if you are already using one.
Lastly, although this is not a part of the seedlist itself, a data pipeline is needed for the seedlist to be utilized. The data pipeline will intake the seedlist data, run the crawler tasks for the social media data collection, and append the seedlist data back to the social media data so that it is ready for analysis. We used Airflow to build and run the pipeline through DAGs (directed acyclic graph). We also built an in-house API to aid the integration between the seedlist, data pipeline steps, and data access. However, an API is a nice-to-have for the data pipeline.
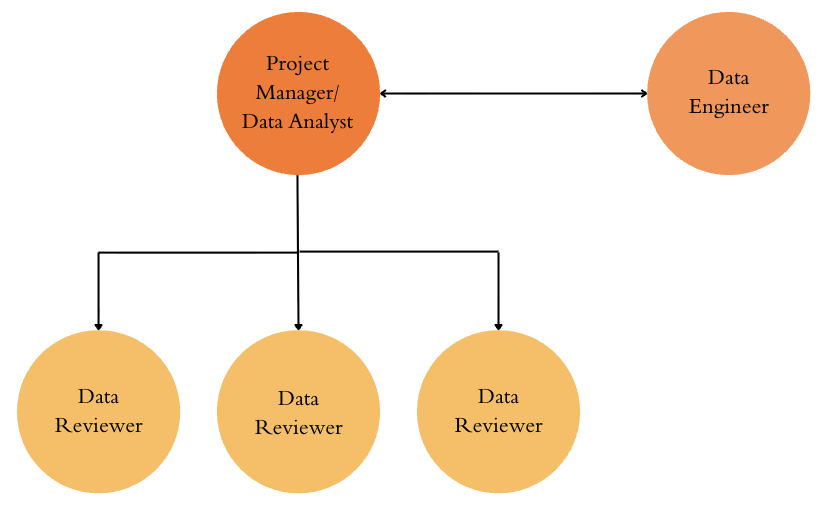
Team requirements
For a seedlist of around 3,000 to 4,000 entities, we recommend a team of 3 to 4 manual data reviewers, a project manager with experience in data analysis, and a data engineer. The exact arrangement may vary based on available resources.
Manual data reviewers make up the largest portion of the team by carrying out entity identification, collection, and verification. While LLM tools can automate parts of this work, such as searching for an entity’s social media handles, there will still be extensive remaining work that needs human review. As a general rule, the less well known an entity is, the more time needed for human review. In our experience, over the course of 3 months, the work of 3 part-time research assistants and part-time support from a data analyst (equivalent to 2 full-time roles) allowed us to compile roughly 3000 entities with 6 demographic variables across 6 platforms. Ideal data reviewers will be detail-oriented and organized. They should be able to observe and communicate patterns, allowing them to then contribute valuable strategies as they become familiar with the raw data and platform dynamics.
The ideal project manager will have experience as a data analyst. As the project manager, they are responsible for defining requirements, design data structure, planning timelines, and managing the data reviewer team. On the data analyst side, responsibilities include scraping entity data from primary sources, cleaning manually-reviewed data, and uploading the data into the seedlist data pipeline.
Complementing this work, a data engineer builds, updates, and maintains the data pipeline. This role’s responsibilities extend beyond the seedlist, since the data pipeline will oversee the entire data collection and transformation process. The data engineer is the most technical role in the team and an ideal candidate should have experience working with data pipelines in production.
Time Requirements
Manual entity collection and review are the most time-consuming steps of building a seedlist. When the entities are already provided with social media handles, data reviewers simply need to verify that each one meets seedlist criteria, find any missing handles, and fill in simple demographic data (such as province). In this scenario, we found that we were able to review and prepare around 500 entities per week with 60 hours of research assistant work hours.
When entities must be identified from scratch, timelines vary widely. If a complete list exists somewhere – such as the list of parliamentarians – a data analyst can typically extract and prepare it within 1 to 2 days. When no exhaustive list is available, identification becomes a manual process. This is often the case when trying to identify influencer seeds. Time-boxed group sessions using keyword searchers, hashtags, and snowballing techniques have allowed us to generate 200 to 300 entities per 3 hour sessions with 4-7 participants. However, the time needed for manual entity identification will vary greatly based on how broad or narrow the scope of the search is. In all scenarios, after the entities have been collected, additional time will be needed to review and enrich those entities in the same process described above.
After the initial collection, you may choose to enrich the existing seedlist with additional demographic information. Our first attempt at adding gender, year of birth, website and city was fully manual and was halted when we realized that it was taking 60 research assistant hours to enrich 150 entities in a week. In our second attempt, we integrated the LLMs into the process to speed it up. We used an LLM to extract the gender, job, political leaning, province, country, age, and language based off of the entity’s social media biographies. Columns were also generated to indicate the LLM’s level of confidence. Low and medium confidence signaled to the research assistant that they should perform a more in-depth search of the entity’s demographic data. High confidence signaled that the research assistant may simply need to do a quick check of the entity’s social media biography and confirm the LLM-generated data. This method worked much better and allowed research assistants to save time by simply verifying the LLM-generated demographic information. With this method, it took an average of 72 research assistant hours to enrich 1000 entities in a week.
Planning and Defining
Aligning on goals, scope, and definitions early is critical for accurately estimating resource needs. The best project goals are tied to the needs they will address1. In our case, we wanted to continuously collect social media posts from key entities in Canada so that we could monitor and analyze the political Canadian digital ecosystem as a whole. This required identifying politically influential actors in Canada’s social media landscape and across various sectors. With a clear goal established, we were able to narrow the scope to political entities only, including influencers if their content was predominantly politics-related. In the end, our seedlist included Canadian political influencers, news outlets, politicians, government & civil society organizations, and a small number of foreign entities that were relevant to Canadian politics.
Defined goals and scope can then inform the inclusion criteria for each seed type. Because these criteria serve as an instruction manual to data reviewers, they should be standardized and supported by established definitions2. This ensures that the criteria has methodological credibility and can save time from developing criteria and thresholds from scratch. For example, we used the commonly accepted definition of a “nano-influencer” in the marketing world to set the minimum follower count threshold (at least 5 000 followers) for the “influencer” type in our seedlist. On the other hand, limitations in resources, such as the upper limit in daily data flow, may also inform the criteria decisions. At the end of the planning phase, all stakeholders should review and sign off the final requirements and definitions documents.
Building a seedlist is a substantial investment of time, planning, and coordination. Once these foundations are in place, the next step is understanding what a well-structured seedlist actually looks like. In the next post, we will walk through the core components of the seedlist and how it should look as a data table.
- Borrowing from the product management world’s jobs-to-be-done approach, it is helpful to identify the job that your seedlist needs to carry out for your research ↩︎
- You can find an example of our seedlist definitions and criteria document here: Seedlist Definitions and Criteria
↩︎
Leave a Reply